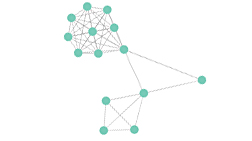

Data mining on DNA methylation data in cancer samples
Distinguishing normal from breast cancer tissue
Breast cancer is the most commonly occurring cancer in women and the second most common cancer overall.
One important aspect of cancer tissues it that they differ from normal tissues in their epigenetic make up, especially in the DNA methylation pattern. In normal cells methylation assures the proper regulation of gene expression and stable gene silencing. DNA methylation is associated with histone modifications, and the interplay of these epigenetic modifications is crucial to regulate the functioning of the genome by changing chromatin architecture.
(...)